一、啥是顾客洞察?
伴随社会的进步,中国顾客所处环境在变,花费观念也在变:大伙从应付生活转变为经营生活、享受生活。在急剧变化的市场环境下,影响花费品牌成长的原因非常多,其中深刻理解顾客,并对消费心理和购买心理、行为变化做出准时的反应是重要的一环,这也就是一般大伙所说的 “顾客洞察”。
大家可以借用 Laddering 模型理解顾客洞察:“从商品属性、功能性利益、情感性利益、价值观等不一样层面来解析顾客的不一样层次的偏好和动机,了解取得他们好感的原因”。
在网络范围,顾客洞察(即用户调查)是商品工作中要紧的一环。只有深入理解用户的行为习惯及背后的的诉求,才能为用户带来好的客户体验。
同样在推广范围,顾客洞察也是所有推广动作的起点,商品定位环节需要挖掘目的群体在不一样场景的诉求,商品推广环节需要找到匹配花费诉求的交流话术触达顾客,已经投入市场的商品需要通过口碑解析来诊断商品的健康度。
二、基于文本云数据的顾客观察
在网络年代到来之前,顾客洞察基本都是通过问卷结合用户访谈的形式展开,这种形式有哪些好处在于,想问什么就可以问什么。但是问题也非常明显,样本量少,用户表达不肯定真实。
而在网络年代,网上已经有很多顾客的表达,如微博、电子商务评论、论坛帖子(比方说孩子树),甚至是一些像医疗专业范围,也有如很大夫等问诊平台承载用户表达。这给顾客洞察提供了更优质的 “土地” :
1)样本量更大。不像过去问卷调查,几百个样本都已经非常大,线上可供研究的顾客是亿级别;
2)场景更丰富。比方说顾客用薯片来炒菜如此的场景,是非常难在问卷中被问出来的;
3)表达更真实。不是被问题引导出来的回答,而是顾客自身说的。
所以围绕着线上文本展开的顾客洞察已被品牌方广泛认同。
三、从文本数据到洞察结果
下面以母婴行业的纸尿裤品类为例,给大伙介绍介绍怎么样基于文本云数据做顾客洞察。
1)确定目的群体,抓取有关数据
在纸尿裤市场,虽然用户是 0-3 岁的孩子,但真正的顾客是母亲群体,而且母亲们从孕期开始就会关注纸尿裤,所以孕期母亲到孩子 1 岁的母亲是大家的目的解析用户。为了获得目的用户的线上言论,笔者通过爬虫技术从相应的母婴论坛去抓取母亲们的数据,这些数据包括基础信息的数据、文本有关数据(帖子、问答)、母亲关注关系的数据,如下图。

2)通过打标签,把文本数据结构化
比方说 “花王纸尿裤实在有点厚”,这句话中包含 “花王纸尿裤”、“有点厚” 两个信息维度。怎么样提取这两个信息维度呢?于是笔者就构建了包含不一样维度信息的关键字词库,假如句子中有相应的关键字,那样这个句子就有对应的维度标签。
举例:假设已经构建好的词库中【纸尿裤品牌-花王】维度包含三个关键字:花王、kao、妙而舒。由于 “花王有点厚”、“kao 的纸尿裤有点厚”、“妙而舒有点厚” 这三句话都匹配上了花王维度中某个关键字,所以都包含花王品牌这个信息点。具体怎么样实操,下面大家详细展开~
(1)构建词库
(a)通过专业信息初步搭建词库框架。比方说构建纸尿裤范围的词库,可以先通过电子商务网站抓取产品有关的信息。以下是京东上可以抓取的帮宝适的品牌信息、功能特征信息。结合一些行业经验,笔者初步梳理出点词库框架,并将这些官方的表达作为初步的词库维度内容。

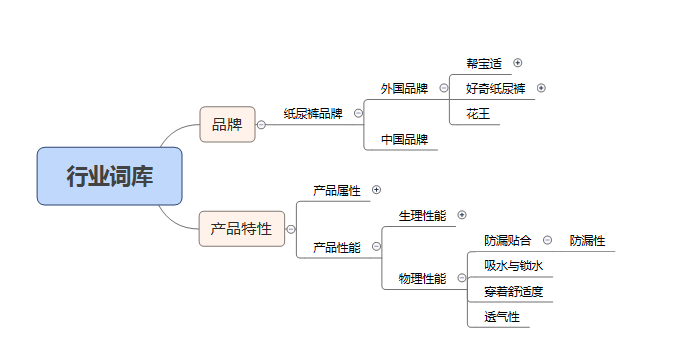
(b)应用 NLP 分词技术,对词库做扩展补充。随机选取适量的文本,可使用 python 软件中的 jieba 包对每一个句子做分词。根据词频的顺序从高到低,把关键字放入到对应的维度中。已有些分类做关键字补充即可;假如没的维度则添加新维度,形成相对完成的词库。
为了更灵活的适配顾客表达,可以使用正则表达式的模式替代一般的关键字。词库落地后的具体形式如下表,其中,tagname 表示词的维度名,keywords 是关键字的正则表达。

(c)人工抽查样本数据,审核词库覆盖率准确率。随机抽取 1000 条文本,遍历看完每一条文本,并对其中没命中的关键字做补充,匹配错的关键字做限定修改(小窍门:依靠软件高亮已经匹配的词,可大大提高审核效率)。
覆盖率=文本中所有重要信息点被覆盖/抽查的文本数目;
某维度准确率=对应维度正确标注的文本数目/命中该维度的文本数目。
当覆盖率90%,词库整体准确率90%,即可将词库投入使用。
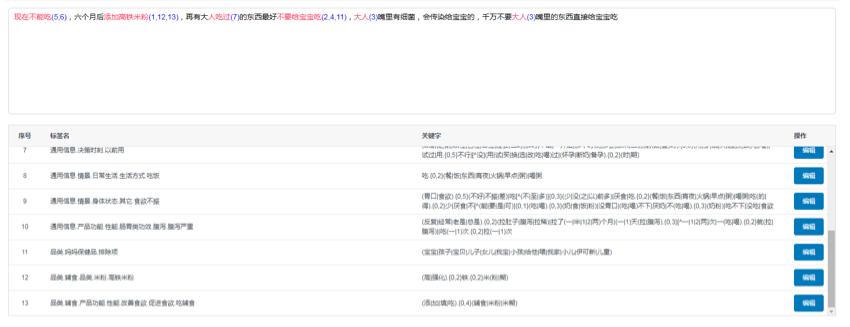
(2)通过词库对文本打标签;
写一个python 小脚本,输入词库,输出打标后的数据。基本步骤如下:
输入文本文件 – 基于肯定的规则对每一个独立的文本做短句切分(比方说根据句号/分号)- 基于词库对每个短句做打标 – 形成标签数据。
具体结果形式如下表(sessionid 即切分的短句 id),基于标签数据就可以做维度的交叉解析。

(3)情感辨别
辨别情感主要通过机器学习模型做情感分类。基于词库打标,已经可以从文本中捕捉出对应的「实体-特点」(比方说「花王-透气」),大家进一步抽取适量的数据做情感人工标注(负面/正面/中性)。最后再交由模型去练习,并对更多的文本数据做情感预测。

3)数据解析
文本数据结构化后,笔者就可以对顾客进行挖掘解析。下面以品类市场的需要解析、品牌认知的差异解析为例子展开说明。
(1)品类市场的的需要解析
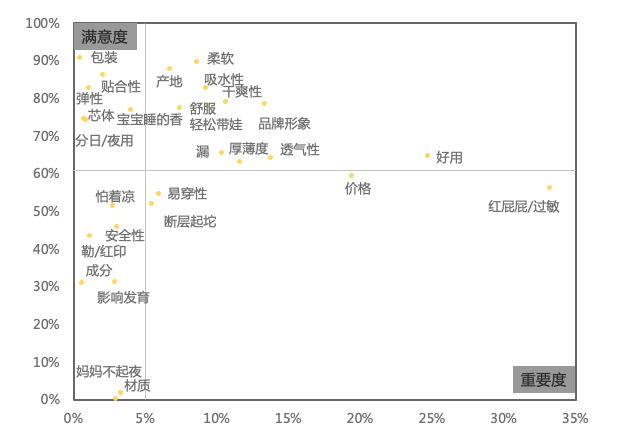
解析纸尿裤品类文本对不一样需要的提及量,和不一样需要的正向言论比率,可以发现 “红屁屁/过敏” 是目前顾客觉得尤为重要,且并没非常不错被满足的需要点。依据需要要紧度、需要认可度两个公式,得出相应结果,如下图。
需要要紧度=某需要的关注用户数/提及纸尿裤品类或品牌的用户数;
需要认可度=某需要的正向表达言论数/某需要的提及言论数。
(2)品牌认知的差异解析
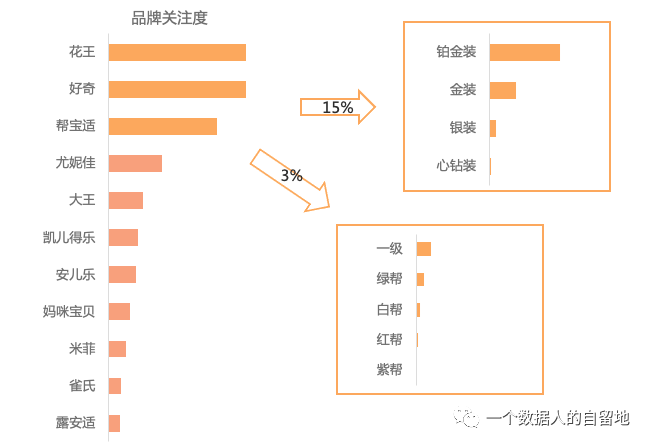
从有品牌认知的顾客中看,不一样品牌的提及量具备显著差别(如下图)。
花王、好奇、帮宝适是最受关注的 TOP3 品牌,其中,好奇和第一名花王的差距很小;
好奇的系列辨识度要远高于帮宝适,其中,帮宝适品牌中仅 3% 的用户会明确提及商品系列。
品牌关注度=提及某品牌的用户数/提及任意品牌的用户数。
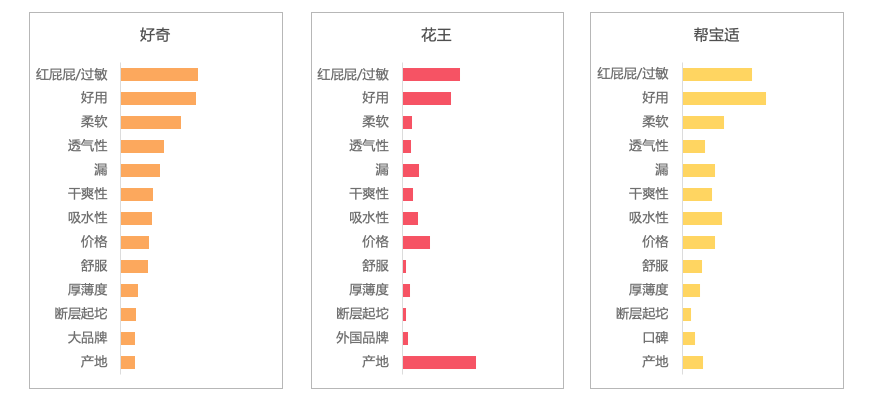
从顾客的正面评价中不一样需要点的分布看,用户选择各品牌是什么原因主如果(如下图):
「不红屁屁/过敏」「好使」是品牌都被顾客认同的点;
好奇更被顾客认同的是「不红屁屁/过敏」、「柔软」、「透气性」;
花王更被认同的是「产地」;
帮宝适更被认同的是「吸水性」、「价钱」。
概括:
本文的目的在于以案例的方法让大伙理解怎么样通过文本数据进行顾客洞察,假如工作中有有关数据场景的可根据文章的思路进行基础实操。
-END-